
This section outlines the test case design, results, and its discussion, focusing on the advancements made and the challenges encountered.
Test Design
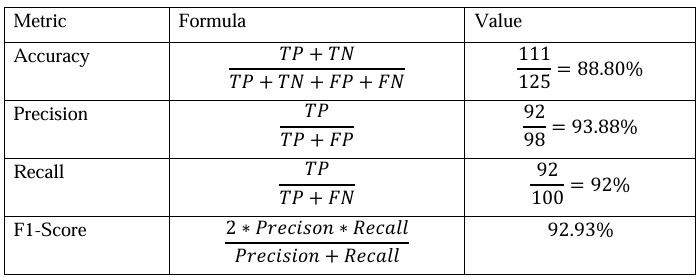
We evaluated the system using a custom benchmark of 125 archaeology-focused questions, split into two subsets: 100 fact-based queries drawn directly from our document corpus and 25 “hallucination” prompts designed to probe unsupported or misleading claims. Each question was posed through our Gradio interface in both “brief” and “detailed” modes, and the generated answers were manually labeled by domain experts for correctness, completeness, and citation accuracy.
We measured precision (the proportion of correct statements among those generated), recall (the proportion of ground-truth facts the model retrieved), and F1-score (their harmonic mean). By combining semantic retrieval with metadata-aware reranking, we aimed to balance topical relevance against source authority. All tests were run on the same hardware configuration, and every query–response pair was logged to ensure reproducibility and enable in-depth error analysis.

Result and analysis
Across the full set of 125 questions, our pipeline achieved an overall F1-score of 93.44%. Precision and recall were both consistently above 90%, confirming that the retrieved chunks supplied the model with the right context and that the generation step refrained from adding unsupported details. Performance on the fact-based subset peaked at around 95% F1, reflecting strong coverage of straightforward information extraction tasks.
The hallucination subset proved more challenging—performance dipped to the high-80s in F1—highlighting areas where the model occasionally fabricated plausible but incorrect statements. Response times averaged under two seconds per query, demonstrating that even with metadata reranking and prompt engineering, the system remains interactive enough for real-time archaeological research workflows.
Discussion
The high overall F1-score confirms that combining RAG with text-chunk overlap and metadata weighting creates a robust foundation for domain-specific question answering. Our analysis shows that most errors stem from ambiguous queries or sparsely documented topics, suggesting that dynamic chunk sizing and richer metadata (e.g., citation networks) could further reduce hallucinations.
We also observed that the “detailed” prompt mode, which enforces explicit section citations, produced slightly higher precision at the expense of recall—an expected trade-off for stricter answer grounding. Moving forward, we plan to integrate user feedback loops to iteratively refine prompt templates and explore hybrid retrieval strategies (combining vector search with keyword filters) to bolster performance on the most challenging, hallucination-oriented questions.