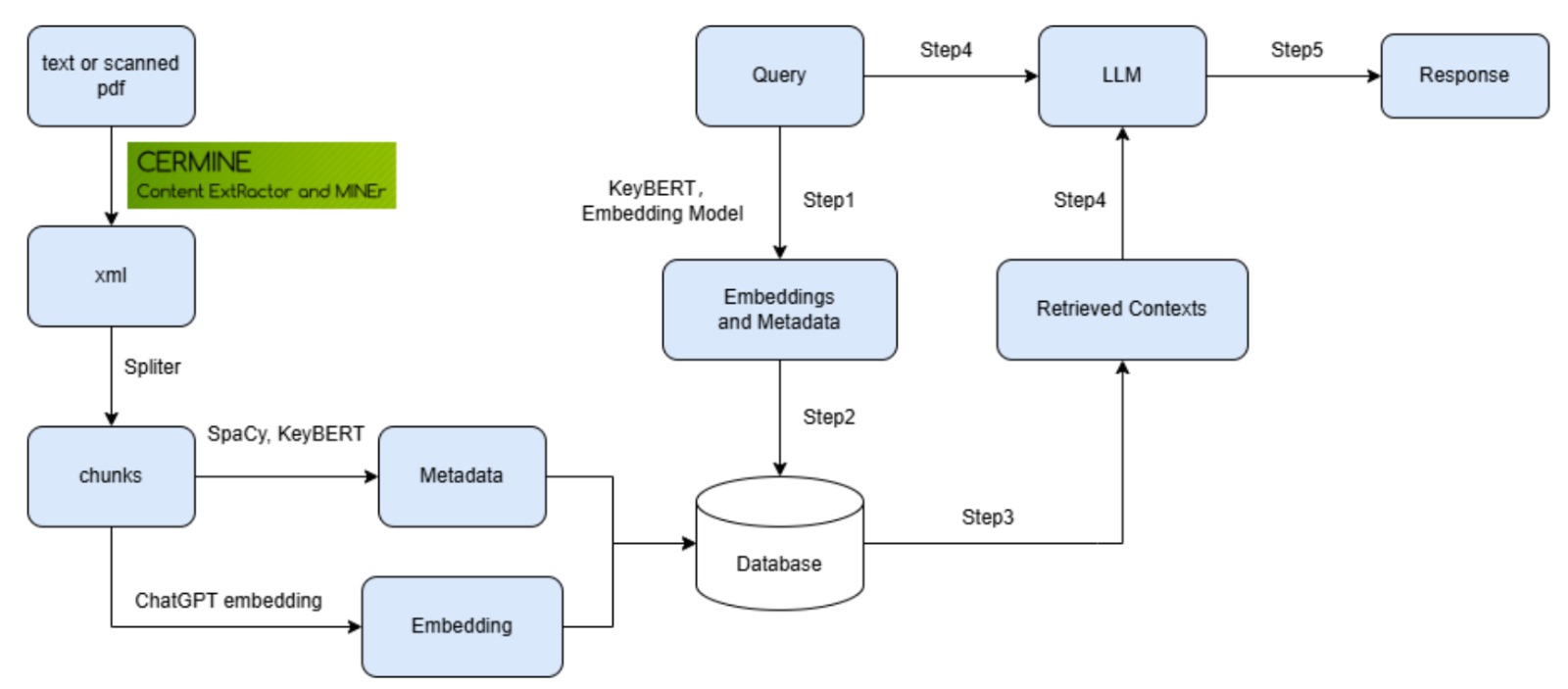
Data Processing & Preparation
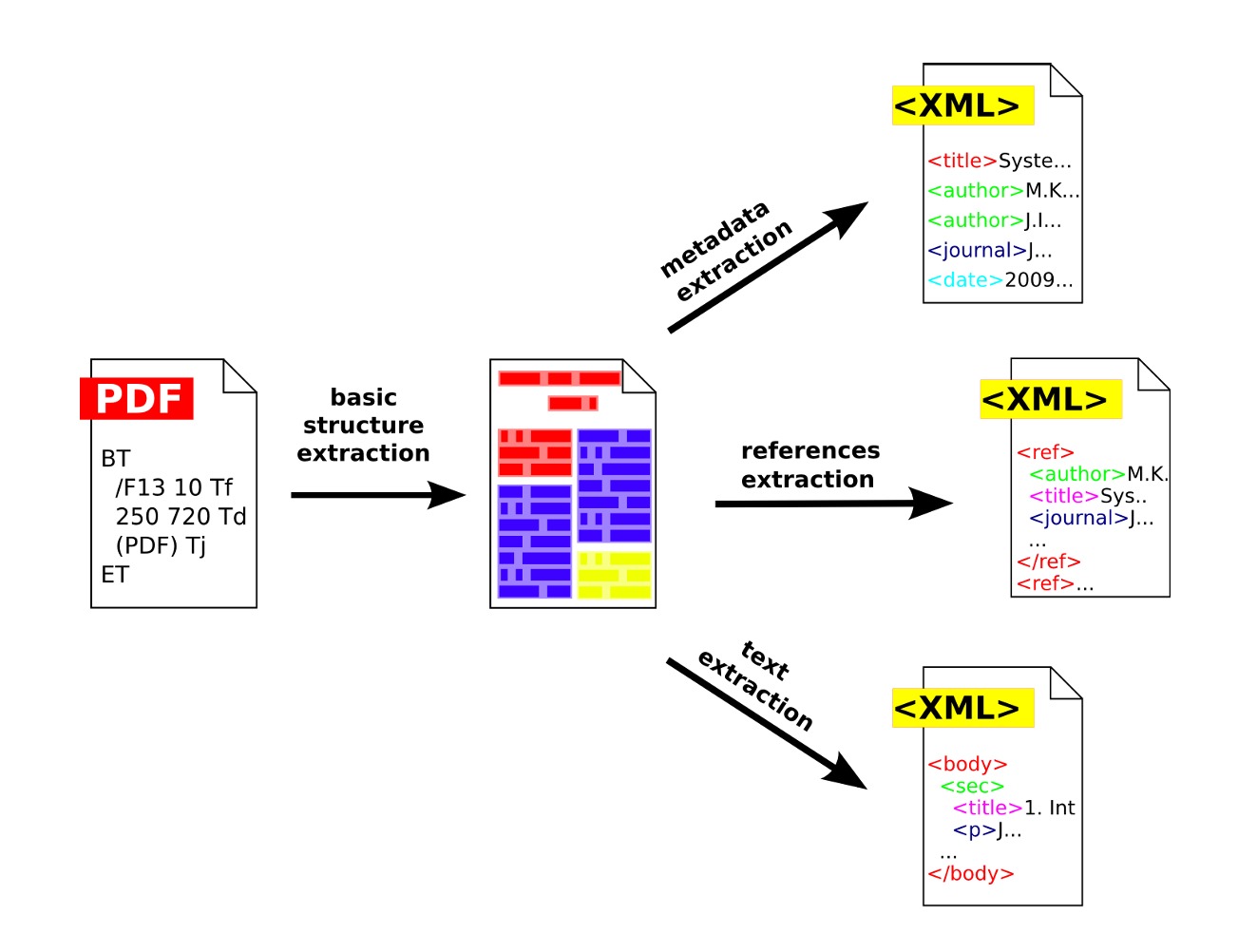
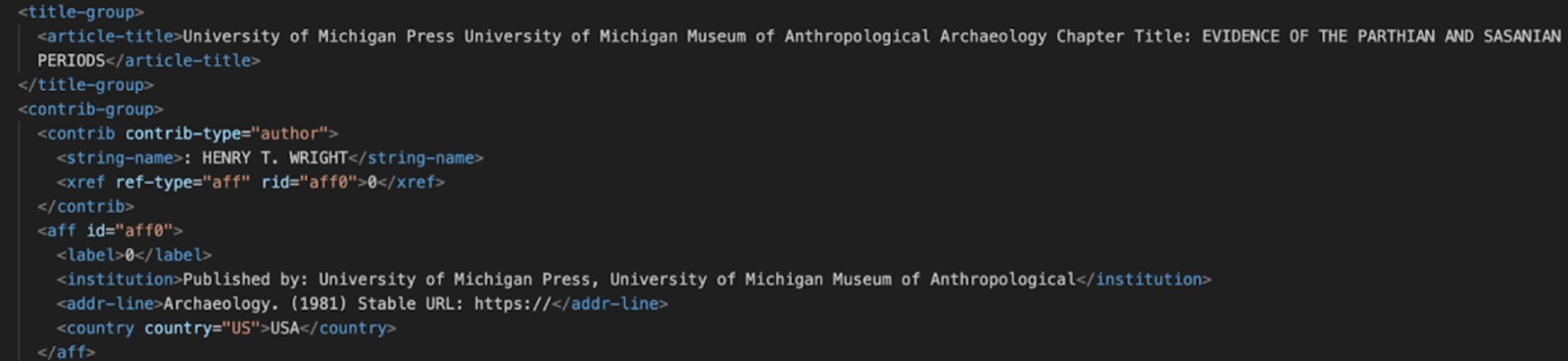
To kick off the pipeline, we first transform raw PDF publications into a structured XML format. This involves leveraging the CERMINE API to automatically extract the document’s logical structure—headings, paragraphs, figures, and tables—then cleaning out empty or malformed tags. Once the XML is in a reliable shape, key metadata fields like title, author, publication date, and section labels are parsed into a searchable index. Capturing this metadata up front not only preserves the scholarly context (e.g., who wrote a paper and when) but also feeds into downstream reranking, ensuring that more authoritative or recent sources can be surfaced first.
With a clean XML backbone and metadata in hand, the next step is chunking the body text into overlapping segments that balance granularity with context retention. We experimented with character-based splitters tuned to roughly 1,000–1,200 characters per chunk, allowing for sufficient semantic cohesion without creating unwieldy passages. Overlaps of 200 characters help bridge topic boundaries, so a discussion of “ceramic typology” in one chunk doesn’t abruptly end before “stratigraphic layers” pick up. Each resulting text snippet is then wrapped in a simple JSON structure that pairs the raw text with its source metadata. Finally, these JSON documents are passed through an embedding model (e.g., OpenAI’s embedding API), converting each chunk into a high-dimensional vector. All vectors, along with their metadata, are stored persistently in a ChromaDB vector store, ready for fast similarity search.
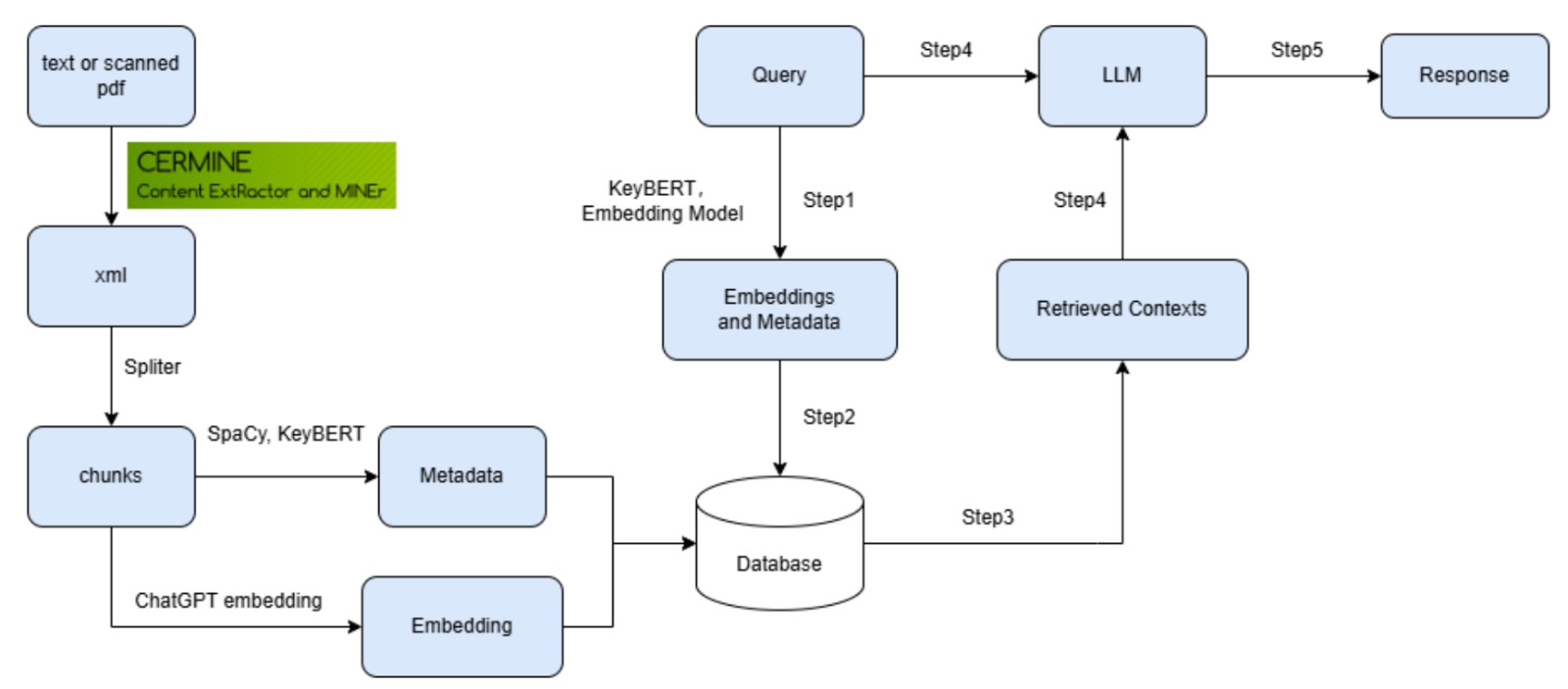
Retrieval-Augmented Generation (RAG) Implementation
In the retrieval phase, user queries are first embedded using the same model that generated the document vectors. The system performs a top-k similarity search against the ChromaDB store to pull the most relevant chunks based on cosine distance. To further refine the results, we apply a simple weighted reranking: chunks whose metadata dates are closer to the query’s implied timeframe or whose source authors have higher publication counts receive a small relevance boost. This hybrid of semantic similarity and metadata weighting helps counterbalance cases where purely vector-based retrieval might overprioritize older or tangentially related passages.
Once the top chunks are selected, they are assembled into a RAG prompt template that guides the generation model to craft concise, context-aware answers. We maintain two prompt modes—“brief” for quick overviews and “detailed” for deeper explanations—so users can choose the level of depth they need. In the detailed mode, the model sees explicit chunk borders and is instructed to cite section labels when appropriate. We also include simple consistency checks in the prompt, such as asking the model to flag unsupported claims.