Why do we care?
The current reward modeling in RLHF cannot reflect preference heterogeneity.
A datapoint for Reinforcement Learning from Human Feedback (RLHF) consists of a prompt, two responses, and a choice between them. However, different clients may choose differently. The current RLHF scheme adopts a user-agnostic, essentially aggregated reward model, which leads to (1) bias towards the majority or (2) conflicting preferences canceled out. This project explores new reward modeling and training methods to preserve preference diversity and cater to different users.
Conditional reward modeling helps.
Instead of integrating all opinions into a marginal distribution, we use a conditional reward modeling formulation that aims to learn the distribution of each individual user. This enables the model to distinguish and preserve diverse preferences and trains it to adapt its behavior to different clients.
We use a Variational Auto-Encoder-based structure from the literature to realize this conditional formulation and propose an adaptive sampling strategy following a continual learning principle that significantly stabilizes and accelerates the training process.
How do we do it?
What have we achieved?
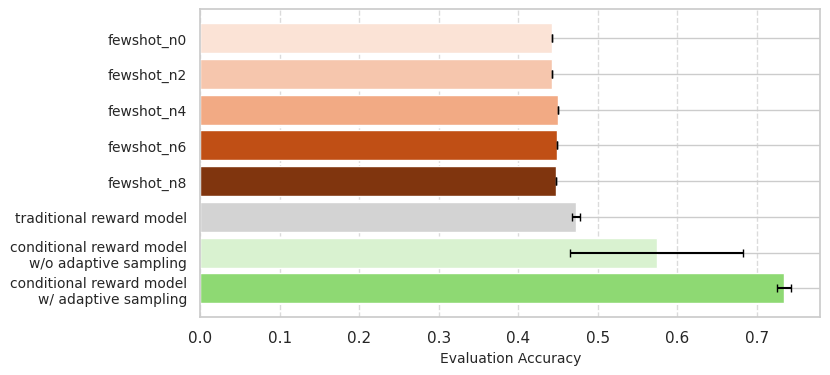
With VAE + adaptive sampling, our conditional reward model greatly outperforms the traditional, user-agnostic reward model, as well as the training-free few-shot prompting baselines.
The adaptive sampling strategy stabilizes training by learning different users sequentially and preventing forgetting, which effectively mitigates the adversarial trend between them.
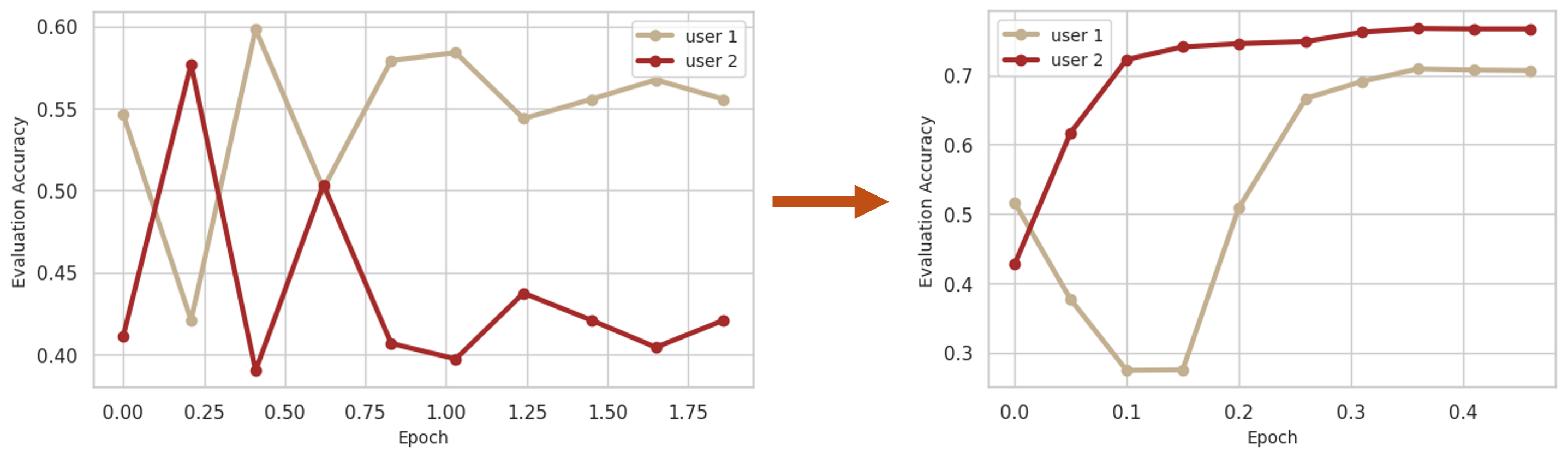
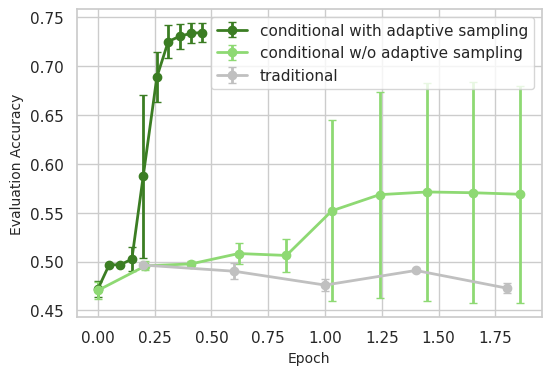
With adaptive sampling, the convergence speed is also largely accelerated, requiring only 1/4 of the original number of steps.
In parallel, we also find that prompting a larger LLM with fine-grained user stories simulates meaningful preferences. Users with similar social occupations tends to demonstrate similar tastes.

Summary
Our major outcomes are summarized as follows:
- We propose conditional reward modeling to preserve diverse human preferences on a specification and conceptual level.
- We experiment with practical methods to realize conditional reward modeling, including few-shot prompting and a VAE-based structure from the literature.
- To solve the training instability issue, we examine several solutions, including multi-objective gradient manipulation techniques, contrastive learning, and propose an effective adaptive sampling strategy that stabilizes and accelerates convergence.
- We investigate using fine-grained user stories and identifiers and simulate preference profiles by prompting a larger model. Results demonstrate diverse opinions and align reasonably with social attributes.
This project contributes to the personalization of LLMs, advancing the goal of creating more adaptive and inclusive AI systems that cater to diverse human preferences. By addressing the heterogeneity of user tastes, this work takes an important step toward ensuring equitable access to high-quality AI tools for users across different backgrounds.
For detailed reports, please check out Documents.