
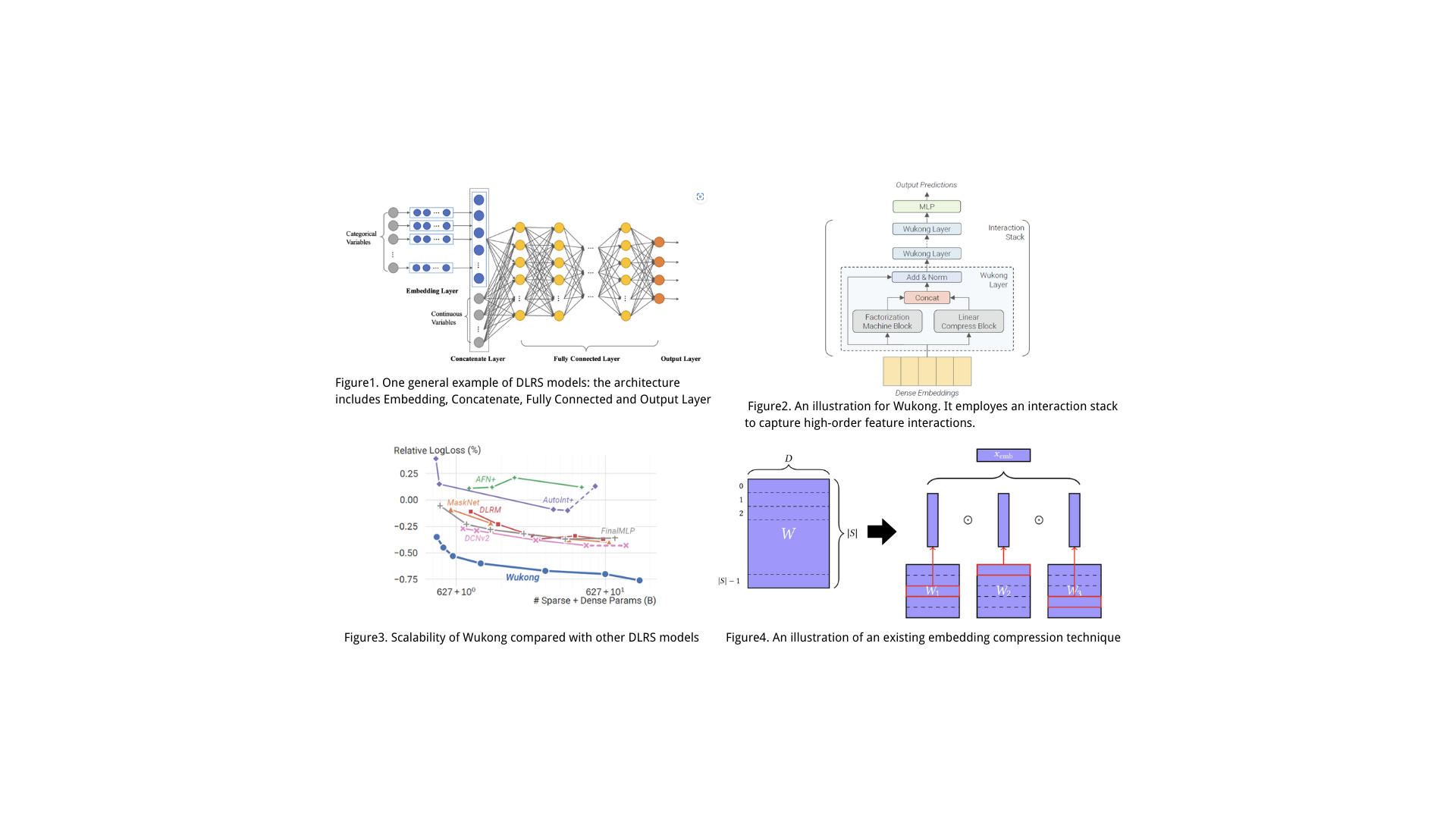
Deep Learning-based Recommendation System (DLRS): From Understanding Scaling Law to Exploring Embedding Compression
Wangjia Zhan
Department of Computer Science
The University of Hong Kong
Introduction
Backgroud knowledge of this project, briefly introducing the research gaps, motivations and objectives.
Motivation
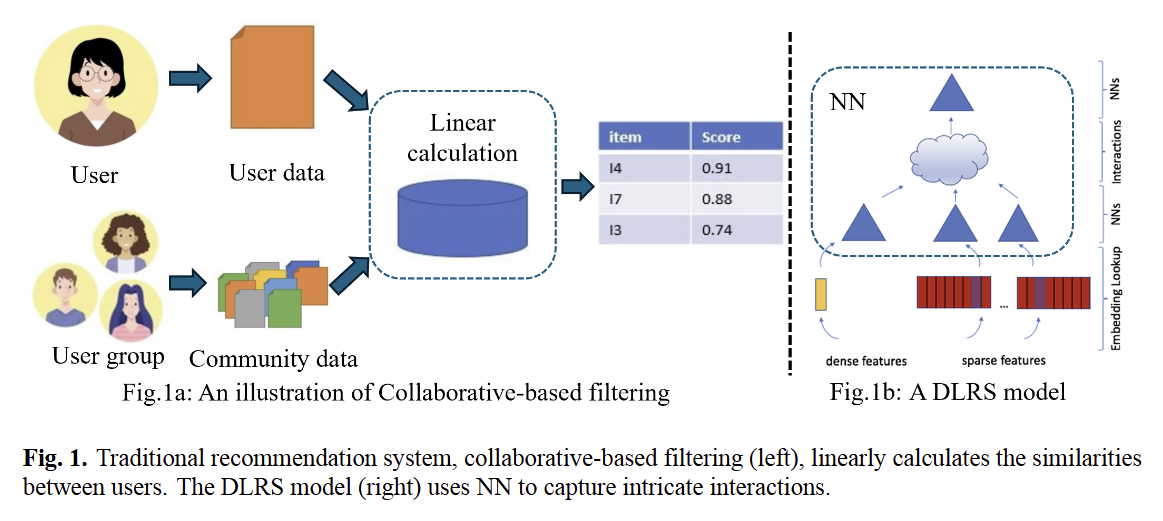
Scaling has become a critical factor in driving improvements in machine learning, especially in language models. However, unlike the NLP domain:
- existing DLRS models do not exhibit a clear parameter scaling law.
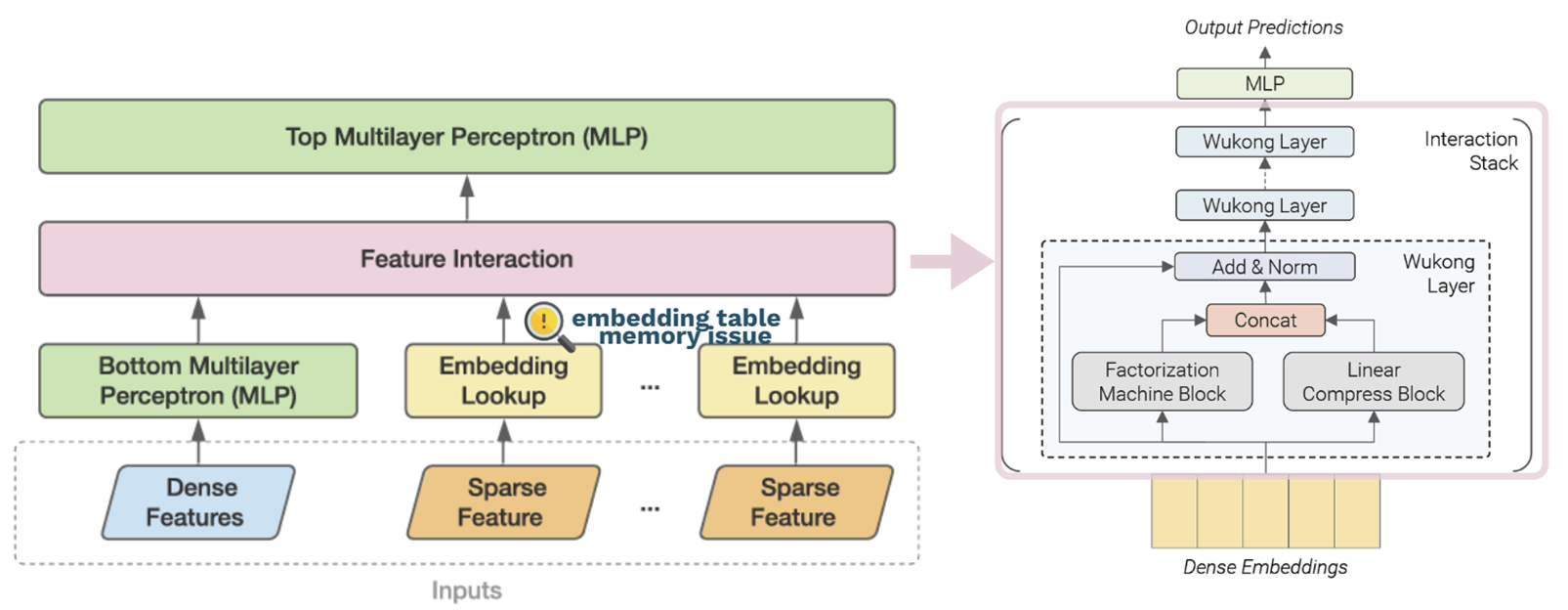
- On the data scaling side, though previous works have demonstrated the effectiveness of increasing training data volume, massive embedding tables will cause significant GPU memory consumption, posing a bottleneck to scaling.
Objective
This project addresses these research gaps by leveraging Wukong (an advanced recommendation model) to:
- Parameter Scaling: Empirically investigate the parameter scaling laws of the Wukong model and identify optimal hyperparameter settings for scalable performance.
- Embedding Compression: Analyze and implement embedding compression techniques to reduce memory usage while preserving accuracy, enabling efficient data scaling.
- Efficient Framework: Develop a memory-efficient framework that integrates parameter and data scaling, demonstrating the potential of DLRS scaling under resource constraints.
Methdologies
The methodologies use in this project is straightforward.
Software/hardware
We use PyTorch and TorchRec for model implementation and distributed training. Experiments are conducted on 1-4 NVIDIA A100/A40 GPUs provided by UIUC NCSA,, depending on the scale.
Dataset Setup
This project focuses on the Click-Through Rate (CTR) prediction task. We validate scalability on CTR benchmarks: including Criteo Kaggle (4GB), Avazu, and MovieLens as small datasets, and the Criteo Terabyte (1.3TB) as industrial scale dataset.
Evaluation Strategy
We examine scaling efficiency along two axes: 1. Data Scaling: Train on datasets ranging across three orders of magnitude. 2. Parameter Scaling: Scale embedding tables, MLPs, over-arch layers and hidden embedding dimensions. Performance is measured by Area Under the Curve (AUC), LogLoss, and Normalized cross Entropy loss (NE).
Algorithm Design
We test various embedding compression methods within Wukong while keeping the dense component fixed. The methods include Hashing, Quotient-Remainder (QR), Multi-Embedding Compression (MEmCom), and Binary Code-based Hashing (BCH).
Results
The following is the experiments and results of this project.
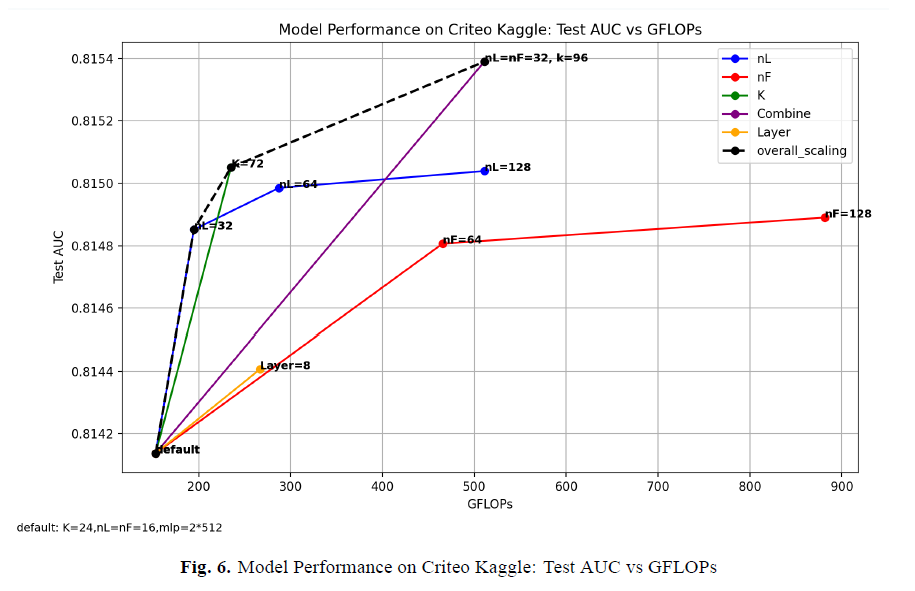
Parameter Scaling
The Wukong model demonstrates clear parameter scaling behavior on both small and industrial-scale datasets, outperforming prior DLRS models. We explore multiple scaling schemes, including:
- nL: number of embeddings generated by LCB,
- nF: number of embeddings generated by FMB
- K: Rank of compressed embeddings in optimized FMB
- Layer: number of Wukong layers in the Interaction Stack.
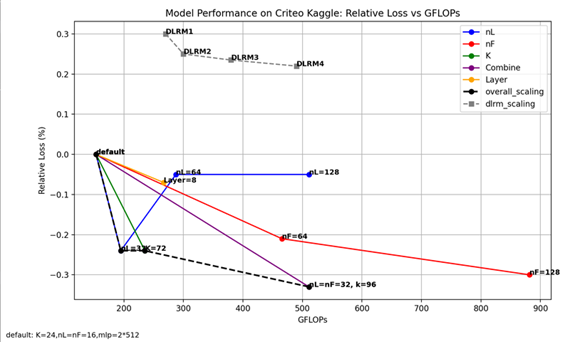
We can see a clear trend of performance improvement as the model size increases, more obvious and effective than others (DLRM); and combined outperforms the single-factor scaling schemes

Embedding Compression
We test various embedding compression methods within Wukong while keeping the dense component fixed. The methods include Hashing, Quotient-Remainder (QR), Multi-Embedding Compression (MEmCom), and Binary Code-based Hashing (BCH).
Embedding Compression
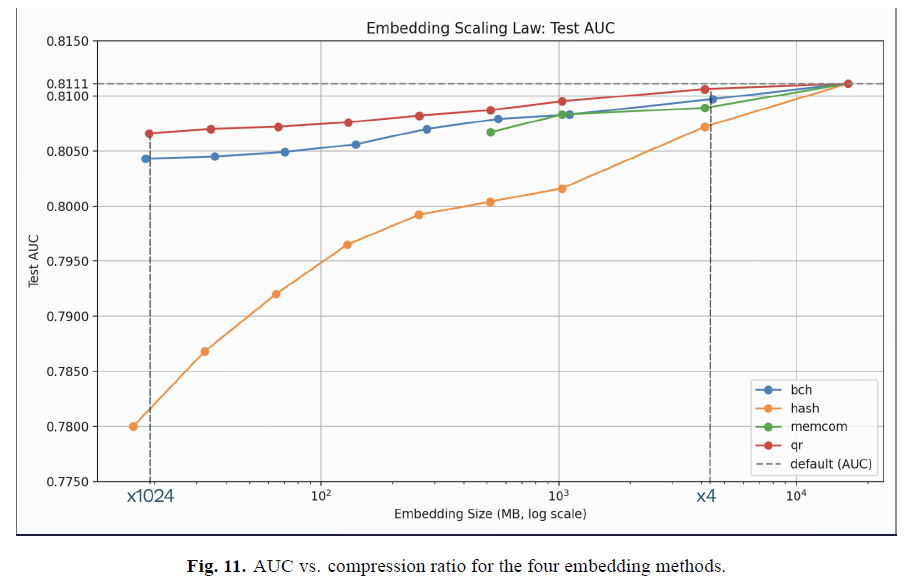
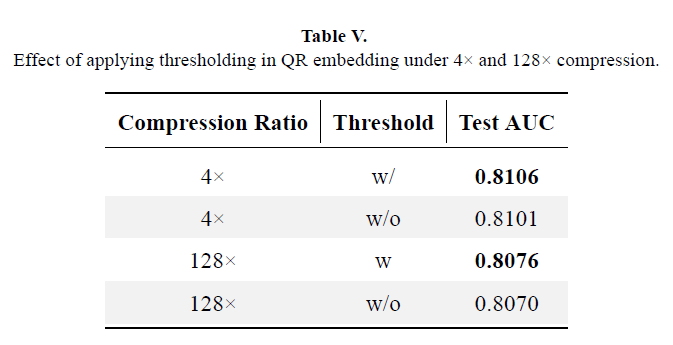
To address memory bottlenecks from large embedding tables, we evaluate four compression methods: QR, MEmCom, BCH and Hashing. As shown in Figure 6, test AUC is reported across compression ratios from 4× to 1024×:
- QR achieves the best performance across all ratios.
- MEmCom and BCH follow closely, maintaining strong performance under compression.
- Naive hashing shows the most degradation, especially at high compression ratios.
We further explore scaling under compression by applying QR. Results (Figure 7) show that performance continues to improve with model size—even with compressed embeddings—indicating that scaling laws still hold under compression.

Efficient Tricks
To further enhance memory savings and performance under extreme compression, we apply the following design strategies:
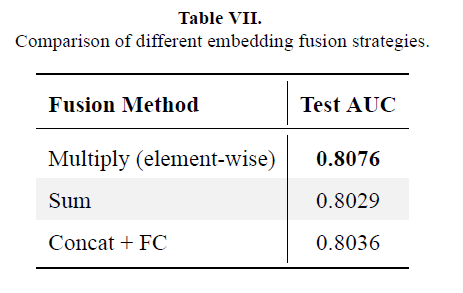
Fusion: Use multiplicative fusion when combining embeddings — it outperforms summation and fully-connected layers.
Threshold: Only compress large embedding tables to avoid unnecessary overhead on small ones.
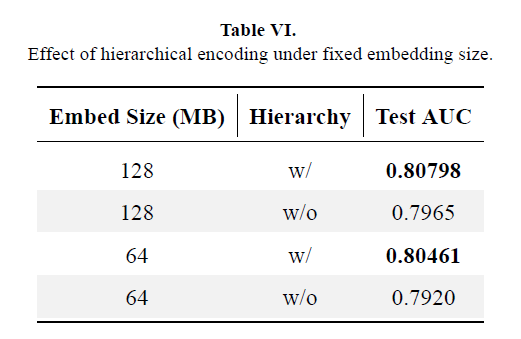
Hierarchic: Apply coarse-to-fine encoding for very large tables to improve compression efficiency.