Human Motion Planning in Spatial Audio Field
Student: Xu, Shuyang (UID: 3035947740)
Supervisor: Prof. Komura, Taku
In this project, we introduce a new dataset, the Acoustic Field-driven Motion (AFM) dataset, which is the first comprehensive dataset that consists of the audio with spatial information and the corresponding human motions.
Based on the AFM dataset, we propose a novel diffsuion-based model, the Acoustic Field-driven Motion Generation (AMoGen) model, which achieves the state-of-the-art performance in human motion synthesis conditioned on spatial audio input.

Achievements
- The AFM Dataset
The AFM dataset is the first comprehensive dataset that consists of the audio with spatial information and the corresponding human motions. It is suitable for training a model used for human motion synthesis in a spatial audio field. The dataset is collected using a Vicon motion capture system.
- The AMoGen Model
The AMoGen model is a diffusion-based model that can synthesize realistic human motions given spatial audio. It is trained and evaluated using the AFM dataset. The generated human motions are expected to have good alignment with both the audio itself and the location of the sound source.
- SOTA Performance
The newly introduced AFM dataste fills in the research gap in the area of 3D human motion synthesis. The AMoGen model also achieves SOTA performance compared with music-to-dance models, both quantitatively and qualitatively.
-

The AFM Dataset
- 9 hours of human motions
- 4M frames
- 70 10-second audio clips
- 27 daily scenarios
- 12 subjects
- 20 common reactions
- 3 motion genres
-
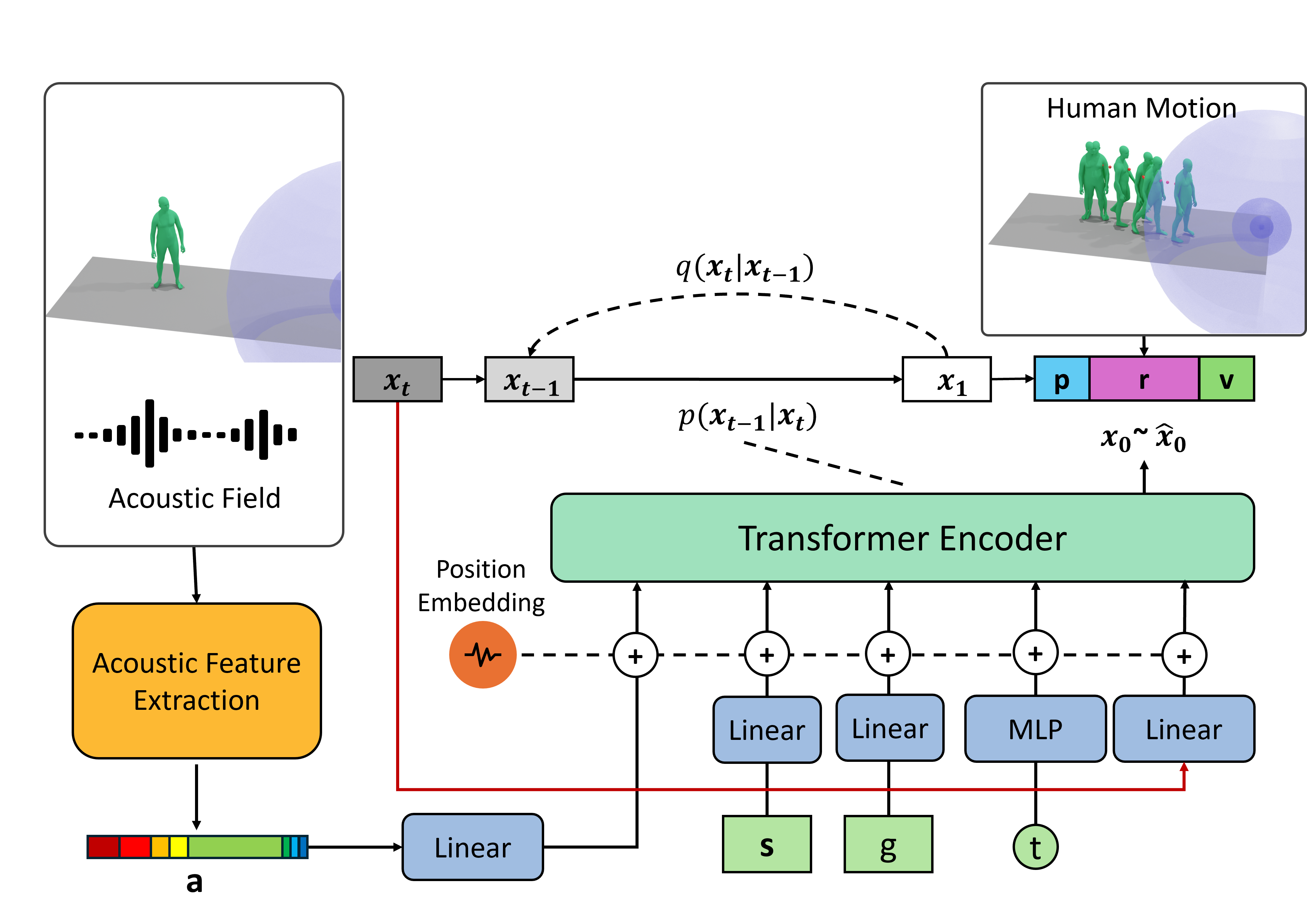
The AMoGen Model
The AMoGen model is a diffusion-based model that can synthesize realistic human motions given spatial audio. The model takes the audio feature vector a, the sound source location s, the motion genre g, the diffusion timestep t, and the noisy motion vector xt as inputs and predict the clean motion sequence x0.
-

Performance
The predicted motion sequence appear to have good alignment with both the audio clip and location of the sound source.