Methodology
This section illustrates the methodology for various stages of the project. The flow of the project is demonstrated on the diagram below, outlining subsections on data collection, data processing, NLP analysis, price prediction models, metrics evaluation and web application dashboard.
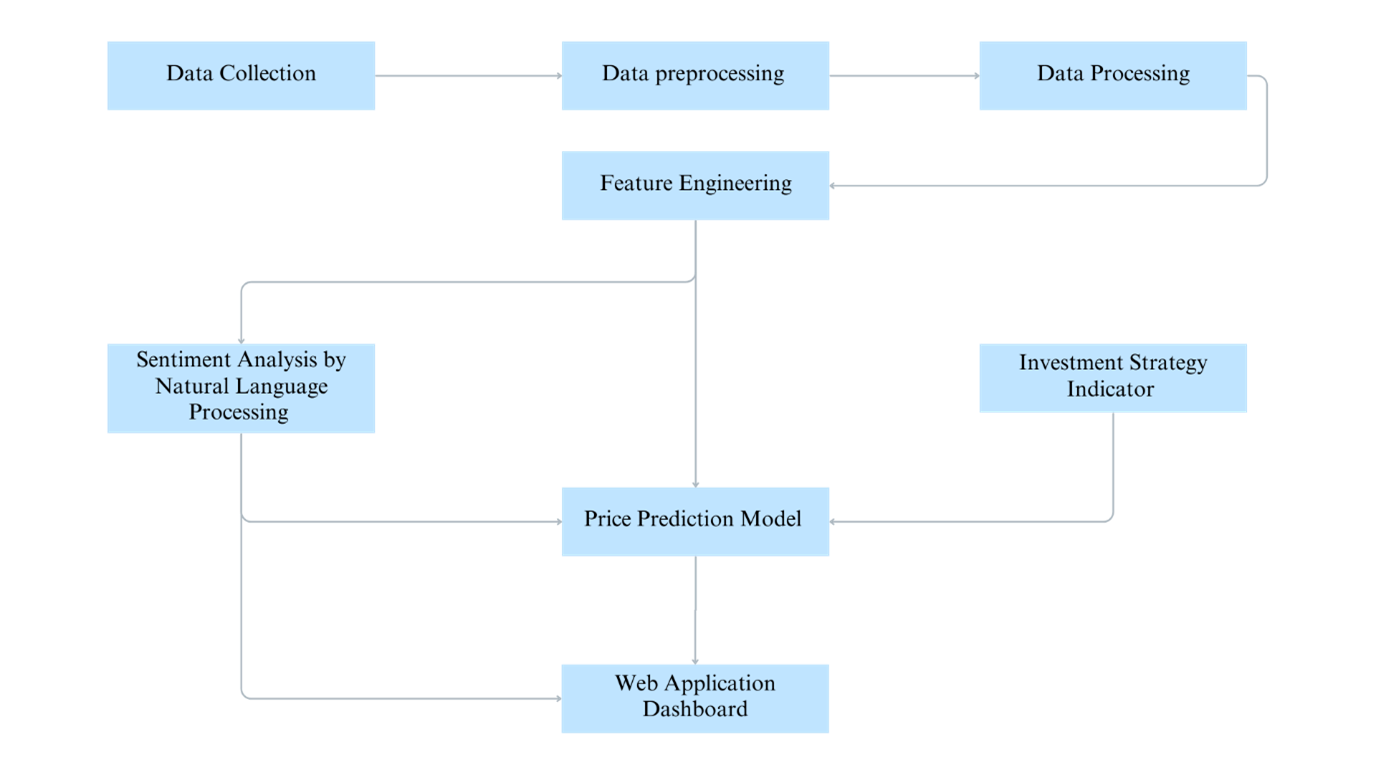
1. Data Collection
The project aims to predict the Bitcoin price from the market condition and the sentiment of investors. The cornerstone of our project is the vast amount of reliable information regarding the Bitcoin. In order to collect the enormous amount of data from various sources on the Internet for analysis, different approaches are adopted based on the type of data. The type of data includes:
- Market Data
The market data consists of Bitcoin-related data and data of other assets.
The market data of Bitcoin includes the open price, the close price and the volume of Bitcoin in various frequencies and the data of other assets includes the open price, the close price, the volume, S&P index, gold spot price, oil price and ETH price. The data of other assets is used to analyze the current market condition for analysis on relationship between market condition and Bitcoin price.
- Social Media Post Data
The social media data includes the title, the content and the traffic of posts regarding Bitcoin from Weibo, Reddit and X (previously Twitter) in different frequency. Bitcoin’s subreddit and follower on X has around 7 million Bitcoin people, this shows that both platforms have a significant influence in the community. These data are essential for us to analyze the sentiment of both Chinese and English Bitcoin community in global.
- News Data
The news data includes the title and content of posts regarding Bitcoin from crypto platforms, including Coindesk and Cointelegraph, and traditional news platform, including Google News and Bloomberg. The news data provides insight on the regulations and market condition of Bitcoin.
To collect an extensive and diverse dataset, two major approaches will be adopted in our project:
The first is Application Programming Interface (API) Approach:
- Market Data
Bitcoin-related data will be collected using the Binance API. The Binance API allows us to collect minute level market data in a fast and accurate way. For data of other assets, we will be using the Yahoo! Finance API to collect accurate and comprehensive market data of different assets and indexes.
- Social Media Post Data
We will be using Weibo API to collect social media post data of Chinese Bitcoin community and Reddit API and X API to collect social media post data of English community.
- News Data
To gather the news data from crypto platforms, we will be using Crypto News API. The Crypto News API allows us to collect news on cryptocurrency news platforms like Coindesk, Cointelegraph and Crypto.new.
The second is Web Scraping Approach:
- News Data
In order to collect news data from traditional news sources, we will be using Beautiful Soup to scrap data from Google News, Bloomberg and Forbes. By gathering news data from traditional news sources, we can have a comprehensive picture on the market condition of Bitcoin.
2. Data Processing
After data collection, the tremendous amount of data, it is very important to perform data cleaning and processing before passing into the models to ensure accuracy and efficiency of model. At this stage, we will first remove the corrupted data, missing values and inaccurate information from the dataset, we will also analyze the outlying data and evaluate the accuracy of the outlying data to ensure the accuracy of the dataset. After data cleansing, we will perform tokenization and lemmatization for textual data using Spacy and Natural Language Toolkit.
3. Natural Language Processing (NLP) Analysis
To analyze the market condition based on news and investor sentiment based on social media posts, we will make use of FinBERT model to analyze the sentiment information of textual data. The FinBERT model outputs the sentiment of news and social media posts. The FinBERT model helps us to convert textual data to sentiment and evaluate the relationship between market sentiment and the price of Bitcoin.
4. Price Prediction Models
Commonly used momentum trading technical indicators will be passed into the model, namely simple moving average (SMA), moving average convergence divergence (MACD), relative strength index (RSI), and momentum indicator (MOM).
After collecting the sentiment of market, the textual data and market data will be passed in various models together with technical indicators to perform price prediction and evaluate the performance across different models and frequency of data. The following models will be used:
- Statistical models such as Auto-Regressive Moving-Average Model (ARMA)
- Machine learning models such as Logistic Regression (LR), Random Forest Regression (RFR) and Support Vector Machine (SVM)
- Deep learning models such as Recurrent Neural Network (RNN) and Long Short-Term Memory Network (LSTM)
5. Metrics Evaluation
In order to compare performance of various models, we will use Root-Mean Squared Error (RMSE), R Squared value and Mean Absolute Scaled Error (MASE) to evaluate the performance of models on price prediction. RMSE shows the overall average prediction error. R2 illustrates how fit the model is and MASE compares the performance of model and naïve forecast.
6. Web Application Dashboard
Lastly, the results of models will be displayed in web interface. The frontend environment will be developed based on React.js and the backend environment will be developed based on Next.js.